parallel_reduce는 .....
일단 코드부터 -_-
코드를 보시면 아시겠지만..
1번은 그냥 for문 돌리고
2번은 parallel_reduce 결과
3번은 parallel_for의 결과..
몇번이고 다시 해보고.. vector대신 배열로도 해보았지만 결과는 마찬가지..
일단 parallel_reduce를 쓰는이유는 parallel_for와 비교해보면 이유를 알수 있습니다.
그런데 원래대로 하자면 tbb의 parallel_for은 operator() const 상태에서만 할수 있기때문에
위와 같이 람다로 fSum을 구하는건 편법(?) 원칙상 안되는 구문입니다..
어쨌든 parallel_reduce로 결과값이 싱글코어로 돌리는것과 동일하게 나올수 있다는건 알겠는데...
가장 중요한 속도가....( 이런 단순한 코드에선 속도가 안나오는건가요 ㅠ.ㅠ)
이런속도라면 그냥 싱글코어가 더 좋겠죠 -ㅅ-;;
간략히 어쨌든 코드 설명하자면..
TbbTest 클래스에서 parallel_for와 달라진건
operator() 에서 const가 빠진것입니다.
const가 빠짐으로 m_fSum에다가 더할수 있게 되었습니다..
그리고 새로이 추가된 void join(const TbbTest &y) 와 TbbTest(TbbTest& y,split) 생성자 2개가 새로이 추가되었습니다.
join은 각각의 스레드에서 합을 구하고 결과를 합처주는 역활을 하는 합수고.
TbbTest(TbbTest& y,split) 생성자는(분할 생성자)의 경우엔 parallel_reduce에서 내부적으로 사용하는 생성자로
하는 역활은 parallel_reduce를 할때 데이터(TbbTest)를 1/2로 분활하는 역활을 하는 생성자이며..
기존의 복사 생성자와 구분하기 위해 더미값 tbb::split를 써준것입니다..
참고로 1/2로 분활할때는 재귀적으로 최소한의 단위(GrainSize)가 될때까지 분활하게 됨니다..
일단 코드부터 -_-
#include <string>
#include <stdio.h>
#include <iostream>
#include <tbb/tbb.h>
#include <vector>
#include <random>
using namespace tbb;
using namespace std;
class TbbTest
{
std::vector<float>* m_vecTest;
public:
void operator() (const tbb::blocked_range<int>&r)
{
std::vector<float>* vecTemp = m_vecTest;
for(int i = r.begin(); i != r.end(); i++)
{
m_fSum += (*vecTemp)[i];
}
}
void join(const TbbTest &y)
{
m_fSum += y.m_fSum;
}
TbbTest(TbbTest& y,split):m_vecTest(y.m_vecTest),m_fSum(0.0f) {}
TbbTest(std::vector<float>* vecTemp):m_vecTest(vecTemp),m_fSum(0.0f) {}
double m_fSum;
};
int _tmain(int argc, _TCHAR* argv[])
{
std::tr1::mt19937 eng;
std::tr1::uniform_real<double> uf(0.01,2.0);
const int MAX_NUM = 10000000;
double fSum = 0;
tick_count start,stop;
vector<float> vecTest(MAX_NUM);
//테스트에 사용될 벡터
for(int i =0;i< MAX_NUM; i++)
{
float ff = static_cast<float>(uf(eng));
vecTest[i]= ff;
}
start = tick_count::now();
for(int i=0; i< MAX_NUM; i++)
{
fSum+= vecTest[i];
}
stop = tick_count::now();
printf("걸린시간 : %f \t합 : %f\n",(stop-start).seconds(),fSum);
start = tick_count::now();
TbbTest tbbTest(&vecTest);
parallel_reduce(blocked_range<int>(0,MAX_NUM,MAX_NUM/4),tbbTest);
stop = tick_count::now();
printf("걸린시간 : %f \t합 : %f\n",(stop-start).seconds(),tbbTest.m_fSum);
fSum = 0;
start = tick_count::now();
parallel_for(blocked_range<int>(0,MAX_NUM,MAX_NUM/4),[&](const blocked_range<int>&r)
{
for(int i = r.begin();i != r.end(); i++)
{
fSum += vecTest[i];
}
});
stop = tick_count::now();
printf("걸린시간 : %f \t합 : %f\n",(stop-start).seconds(),fSum);
return 0;
}
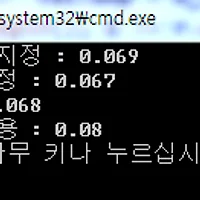
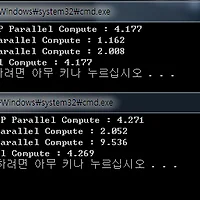
릴리즈모드 속도최적화 끈 상태의 결과
코드를 보시면 아시겠지만..
1번은 그냥 for문 돌리고
2번은 parallel_reduce 결과
3번은 parallel_for의 결과..
몇번이고 다시 해보고.. vector대신 배열로도 해보았지만 결과는 마찬가지..
일단 parallel_reduce를 쓰는이유는 parallel_for와 비교해보면 이유를 알수 있습니다.
그런데 원래대로 하자면 tbb의 parallel_for은 operator() const 상태에서만 할수 있기때문에
위와 같이 람다로 fSum을 구하는건 편법(?) 원칙상 안되는 구문입니다..
어쨌든 parallel_reduce로 결과값이 싱글코어로 돌리는것과 동일하게 나올수 있다는건 알겠는데...
가장 중요한 속도가....( 이런 단순한 코드에선 속도가 안나오는건가요 ㅠ.ㅠ)
이런속도라면 그냥 싱글코어가 더 좋겠죠 -ㅅ-;;
간략히 어쨌든 코드 설명하자면..
TbbTest 클래스에서 parallel_for와 달라진건
operator() 에서 const가 빠진것입니다.
const가 빠짐으로 m_fSum에다가 더할수 있게 되었습니다..
그리고 새로이 추가된 void join(const TbbTest &y) 와 TbbTest(TbbTest& y,split) 생성자 2개가 새로이 추가되었습니다.
join은 각각의 스레드에서 합을 구하고 결과를 합처주는 역활을 하는 합수고.
TbbTest(TbbTest& y,split) 생성자는(분할 생성자)의 경우엔 parallel_reduce에서 내부적으로 사용하는 생성자로
하는 역활은 parallel_reduce를 할때 데이터(TbbTest)를 1/2로 분활하는 역활을 하는 생성자이며..
기존의 복사 생성자와 구분하기 위해 더미값 tbb::split를 써준것입니다..
참고로 1/2로 분활할때는 재귀적으로 최소한의 단위(GrainSize)가 될때까지 분활하게 됨니다..
'병렬프로그래밍' 카테고리의 다른 글
| 람다식을 이용한 TBB의 parallel_for parallel_for_each 에서 tbb::concurrent_unordered_map 을 사용해보자. (0) | 2011.10.26 |
|---|---|
| TBB & PPL의 task_group(task)를 사용해보자.. (2) | 2011.09.09 |
| tbb를 배워보자.. parallel_for의 사용법.. 1 (0) | 2011.08.05 |
| 병렬 프로그래밍(PPL,openMP,TBB)의 for문 속도 비교..!! (2) | 2011.08.04 |